.png)



据我所知,不少NAS玩家是专门为大姐姐们盖了别墅的,但是可能会头疼刮削问题。
本期来介绍一款Docker项目,刮削能力十分强悍。由于原来的工具Movie Data Capture闭源,作者索性自己写了一个Yet Another Movie Data Capture(yamdc),描述它为“一个不太正经的电影元数据刮削工具”。
虽不太正经,但相当🐮🍺,姐姐们的专属影视墙不在话下。
文章分为特性介绍、部署流程、效果展示3部分。关于内容隐藏,防止无关人员看到,大家可以活用EMBY等的账户管理、内容标签过滤、分级内容控制等功能,或者利用NAS的账户文件访问权限设置等来实现。
特性
✅ 适配主流媒体服务器
支持 Jellyfin / Emby / Plex
✅ 丰富的刮削源
✅ 自动化刮削
自动解析 番号
自动下载 封面、演员信息、影片标签
自动匹配 中文翻译(剧情简介)✅ 多种文件命名规则
✅ 强大的 AI 识别
GoFace / PigoFace(可选 AI 人脸识别)
识别演员,进行 自动分类
生成 演员标签✅ Docker 一键部署,简单易用
✅ 本地缓存,避免重复下载
自动缓存封面、元数据
避免重复查询,提升刮削速度
部署流程
以威联通NAS为例,先准备程序的配置文件。文中部署所涉及的相关文件也可点我下载。
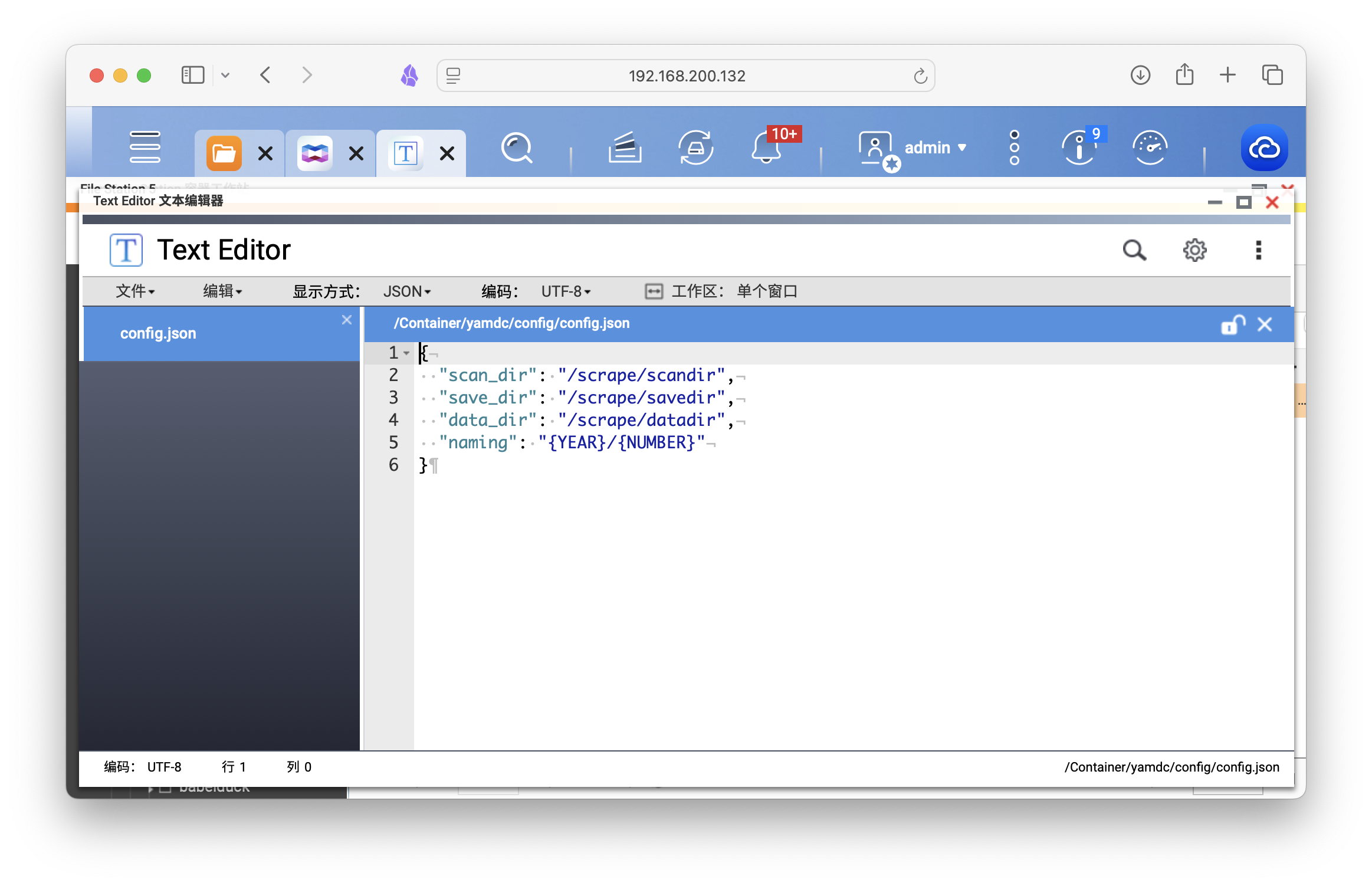
我习惯存放于Docker专用路径/share/Container/yamdc/config,创建好文件夹后,打开Text Editor创建文本文件,将以下代码复制粘贴进去。
{
"scan_dir": "/scrape/scandir",
"save_dir": "/scrape/savedir",
"data_dir": "/scrape/datadir",
"naming": "{NUMBER}"
}
将文档另存为,命名config.json,存放于上面准备好的文件夹下。
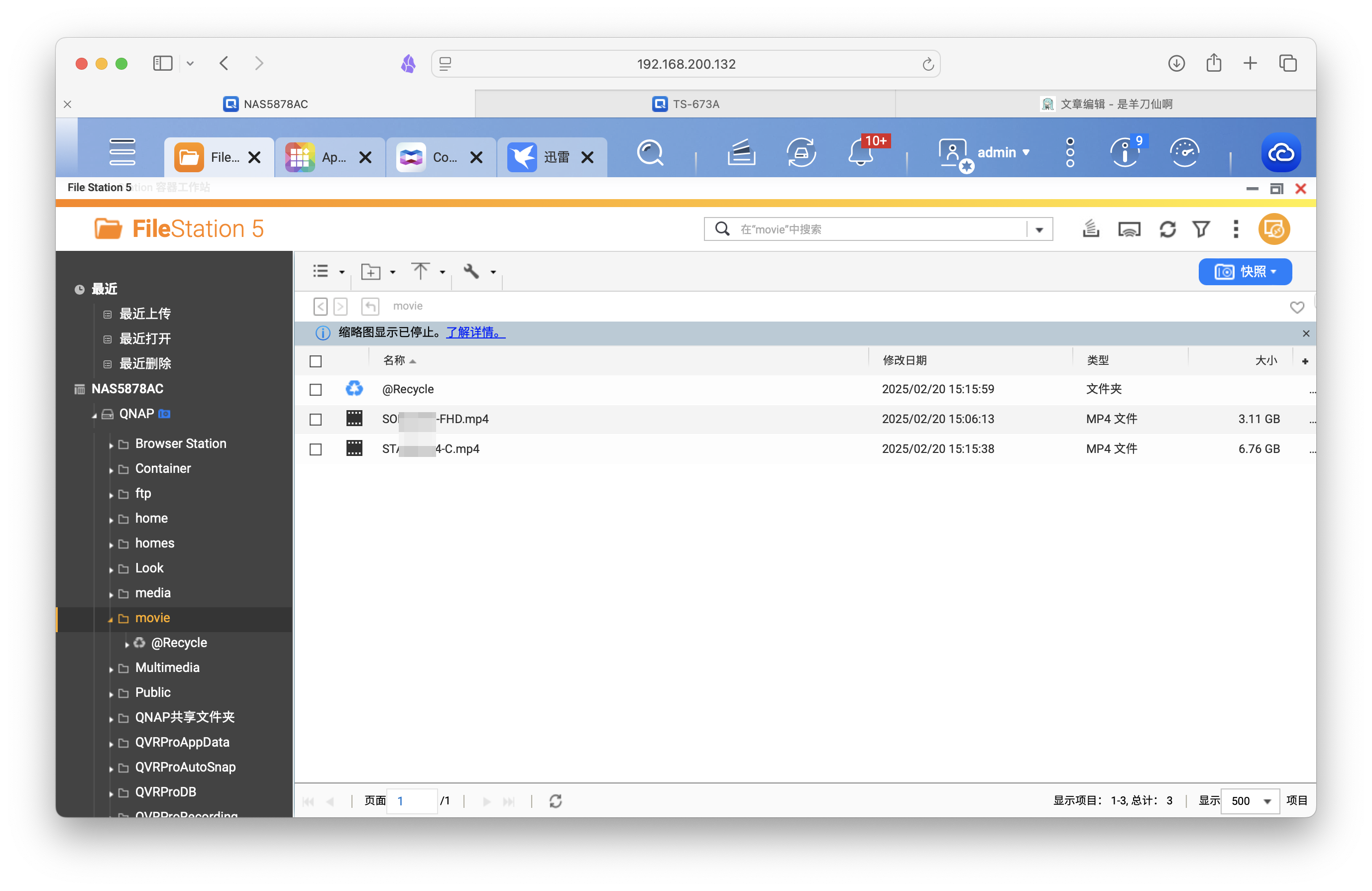
把原片准备好,放在你的文件夹中。
TIPS:
可用的命名标签如下:{DATE}, {YEAR}, {MONTH}, {NUMBER}, {ACTOR}。
工具并不会对番号进行清洗(各种奇奇怪怪的下载站都有自己的命名方式, 无脑清洗可能会导致得到预期外的番号), 用户自己需要对文件进行重命名,否则刮削的时候大概率报错。
当前支持给番号添加特定来后缀来实现添加额外分类, 添加特定水印等能力。
支持的后缀列表及说明(不同的后缀没有顺序限制, 可以同时存在多种后缀)。

打开 Contaienr Station ,创建新的应用程序。
代码如下,可自行修改后粘贴并创建:
version: '3' # 最新版该行可删除
services:
yamdc:
image: xxxsen/yamdc:latest
container_name: yamdc
user: "0:0"
environment:
- ENABLE_GO_FACE_RECOGNIZER=false # 屏蔽掉go-face的初始化
volumes:
- /share/movie:/scrape/scandir/scandir # 原片存放位置,刮削过程中影片会被自动转移
- /share/Look:/scrape/savedir # 刮削好的数据包括影片会转存到这里
- /share/Container/yamdc/datadir:/scrape/datadir # 数据目录,也是刮削数据中转站
- /share/Container/yamdc/config:/config # 配置文件目录
command: --config=/config/config.json
这里直接点击创建,就会自动刮削,刮削完成的电影会被存储到/share/Look下,刮削完毕后容器会自动停止。也就是说,咱们每次要刮削,重新跑一边程序就可以。
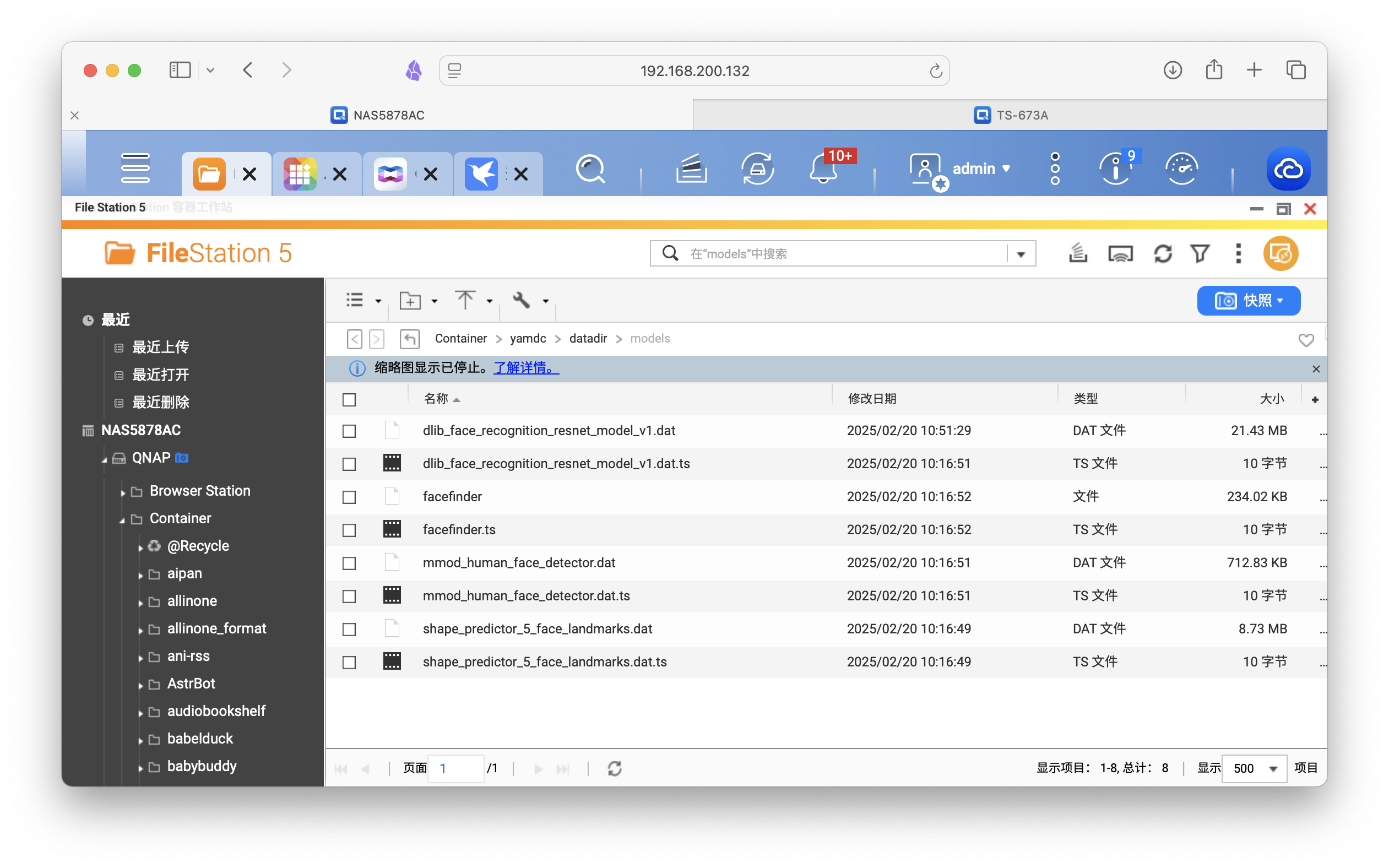
程序依赖go-face进行人脸识别, 以用于识别图片中的人脸并进行截图, 这个库需要有对应的模型文件, 程序启动的时候, 会检测模型文件是否存在, 如果不存在, 则会自动下载模型文件到数据目录下。
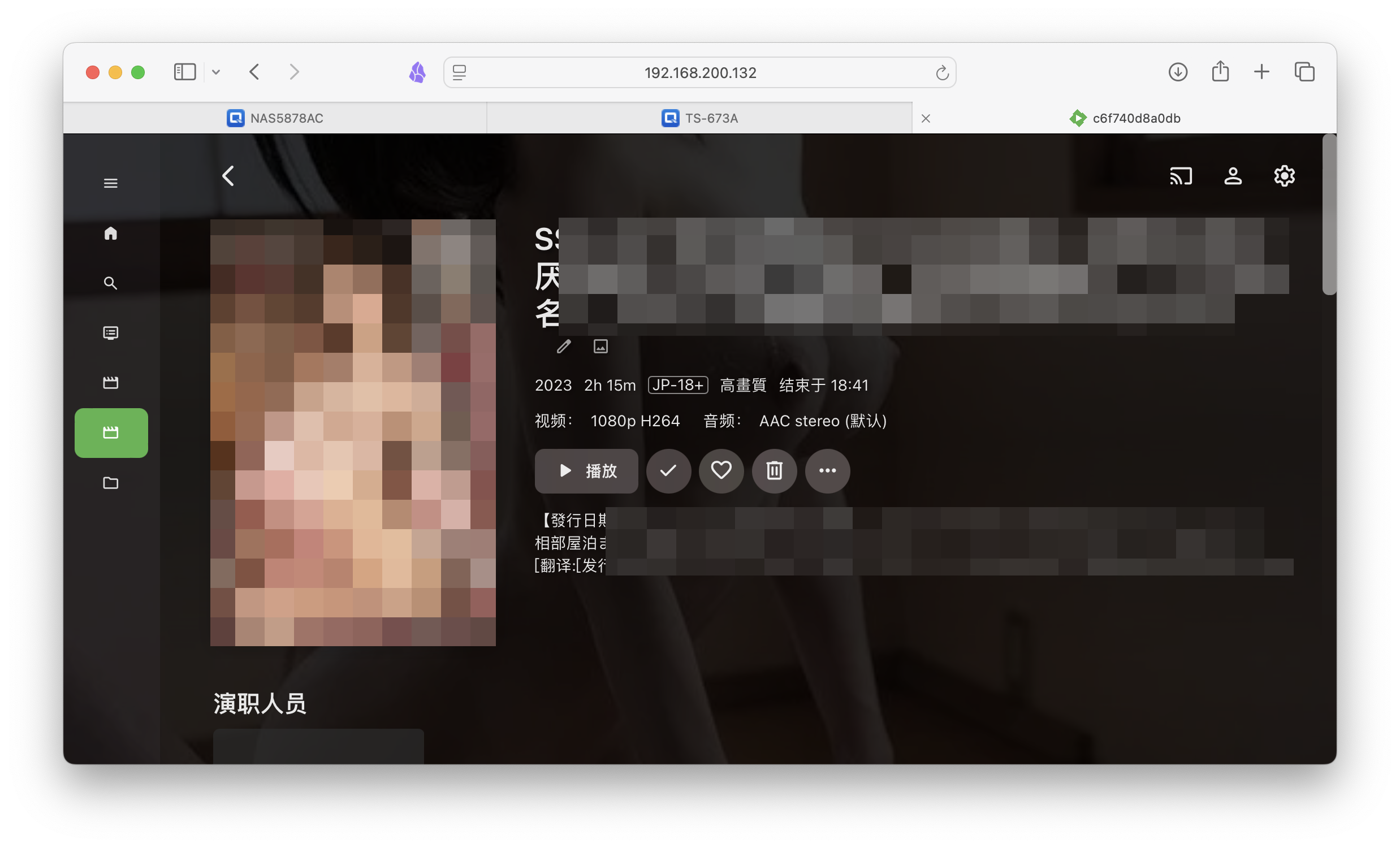
效果展示
准备了三部~碍于机械盘的读写速度,数据量较大时程序可能跑的时间也会延长,耐心等待就行。
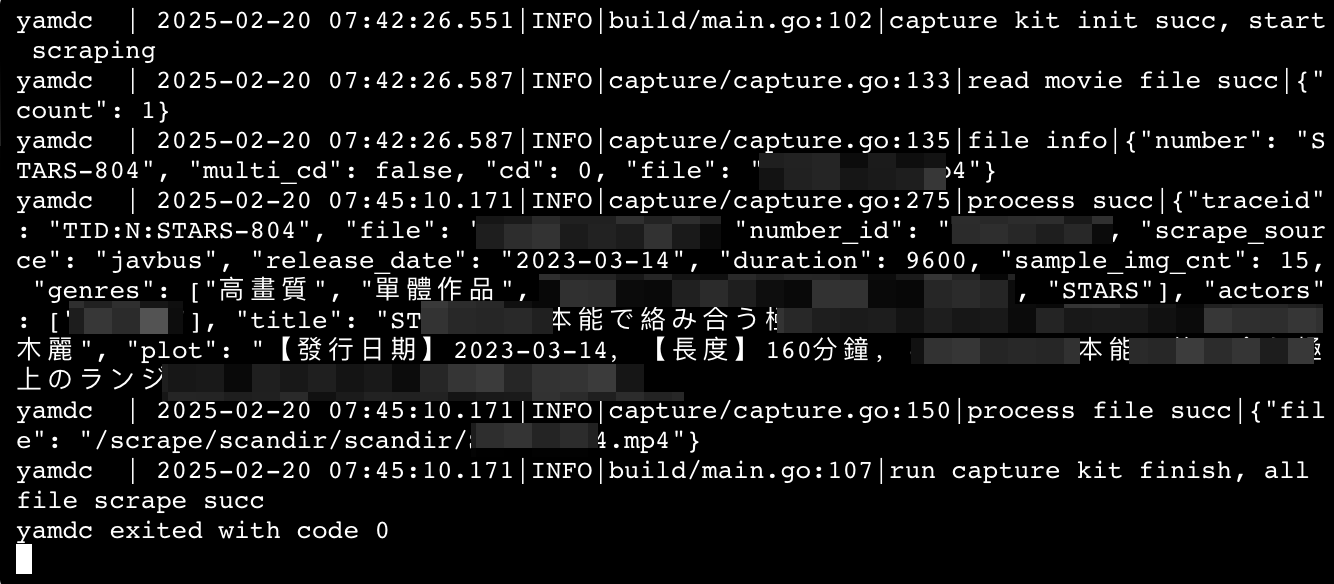
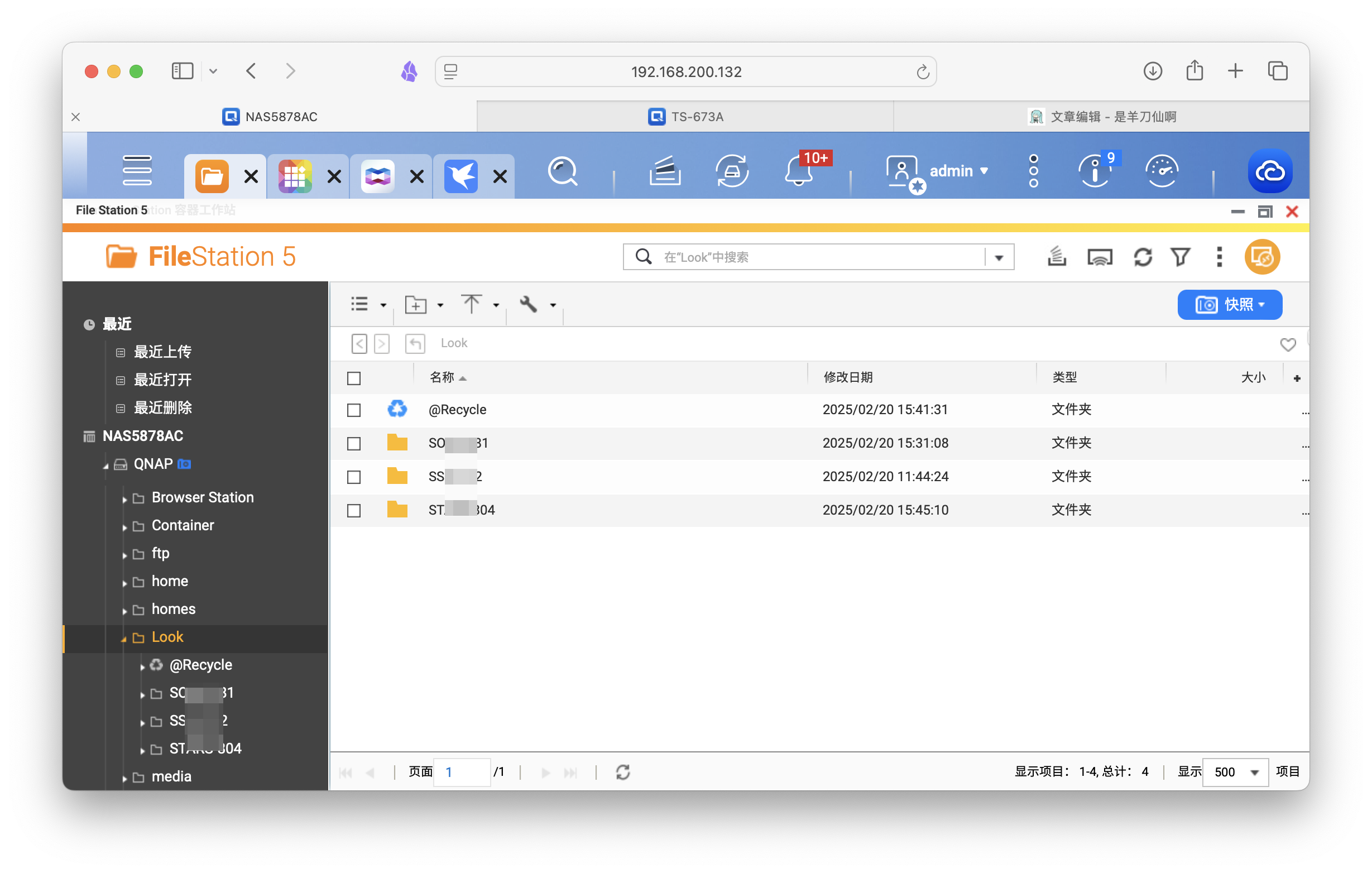
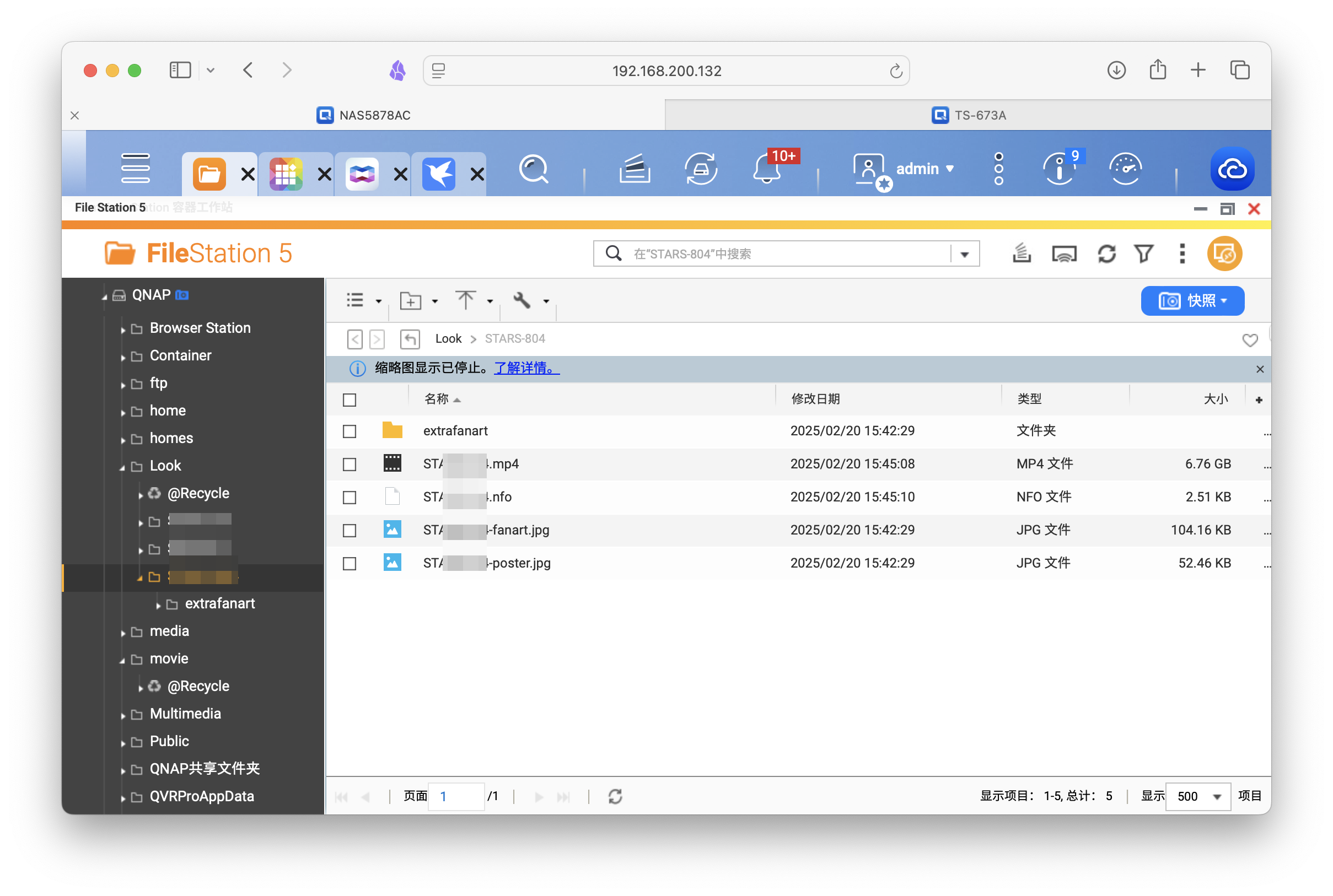
刮削完毕后,自动转存到所设目录下,包括元数据文件、海报、原片等。
整到emby,效果还不错的。。。多的我也不展示了= =
评论区