.png)



本次来介绍一款能够借助 AI 大模型,实现一键生成解说文案并自动剪辑视频的项目:NarratoAI。
在我身边,已经有朋友通过 AI 生成视频,剪辑后将内容投放到视频平台,成功实现了变现。当然,AI 生成视频的质量和最终呈现效果,并不是简单点一下按钮就能决定的,它通常受到提示词设计、底层模型能力、参考素材质量以及关键参数设置等多方面因素影响。此外,不同工作流的组合方式,以及生成时长带来的内容衰减问题,也都会对结果产生影响。
AI 最终做出来的内容,往往是千人千面的。同样的工具,不同的人去用,效果可能差别很大,所以这件事本质上还是需要不断理解、尝试和学习。本文并不能大家如何靠它赚钱,但如果你想自己搭建起来体验一下、研究一下它的玩法,那么拿来玩一玩还是很有意思的。
项目介绍
完整项目名:linyqh/NarratoAI,可于GitHub搜索。
NarratoAI是一款自动化影视解说,基于LLM实现文本编写、自动化视频剪辑、配音和字幕生成的一站式流程,助力高效内容创作。可接入 OPAI、DeepSeek、Gemini 兼容网关、Qwen、SiliconFlow、OpenRouter 等服务。
它更适合用来提升效率、搭建 AI 视频工作流,而不是替代专业剪辑软件去做特别复杂的后期。同时,这类项目也有比较强的可调性。不同的提示词、素材内容、模型能力和参数设置,都会直接影响最终效果,所以它既是一个工具,也带有一定的“调教”属性。
部署流程
以威联通NAS为例,通过Docker的方式进行部署。
不过本次作者并没有提供官方镜像,因此需要我们自行构建。
打开SSH工具连接你的NAS,依次输入以下指令:
# 进入常用Docker目录下
cd /share/Container
# Git 拉取
git clone https://github.com/linyqh/NarratoAI.git
# 进入文件
cd NarratoAI
# 修改文件名
cp config.example.toml config.toml
# 构建
docker compose up -d
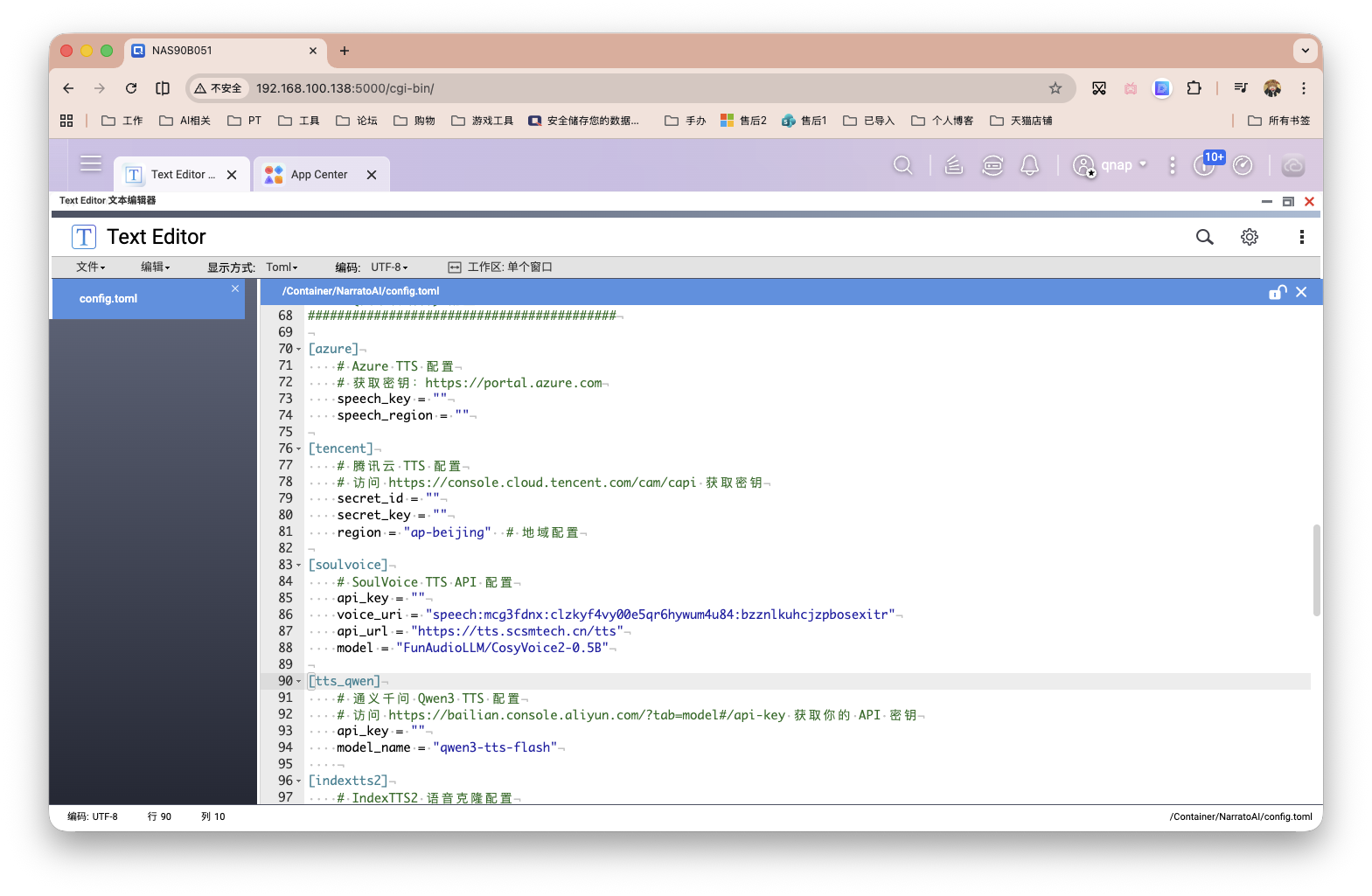
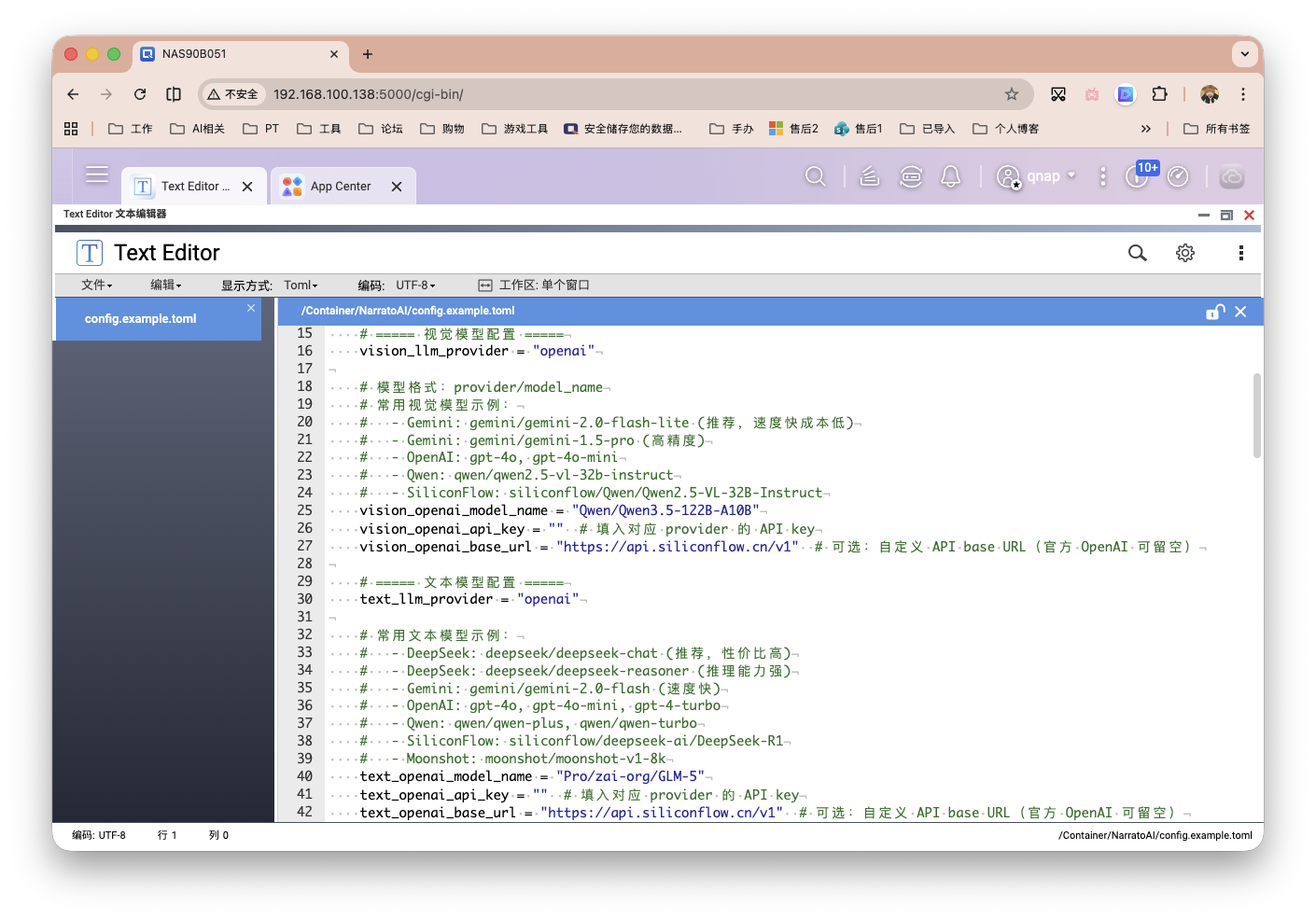
关于config.toml,其中是API Key的相关配置。包含了 LLM 视觉、文本模型配置,TTS配置两项。这个没啥难度,选择好你的服务商平台,填入参数即可。项目作者也还另外推荐了一个开源的零样本TTS文本转语音服务,大家可以部署联动使用:index-tts/index-tts。
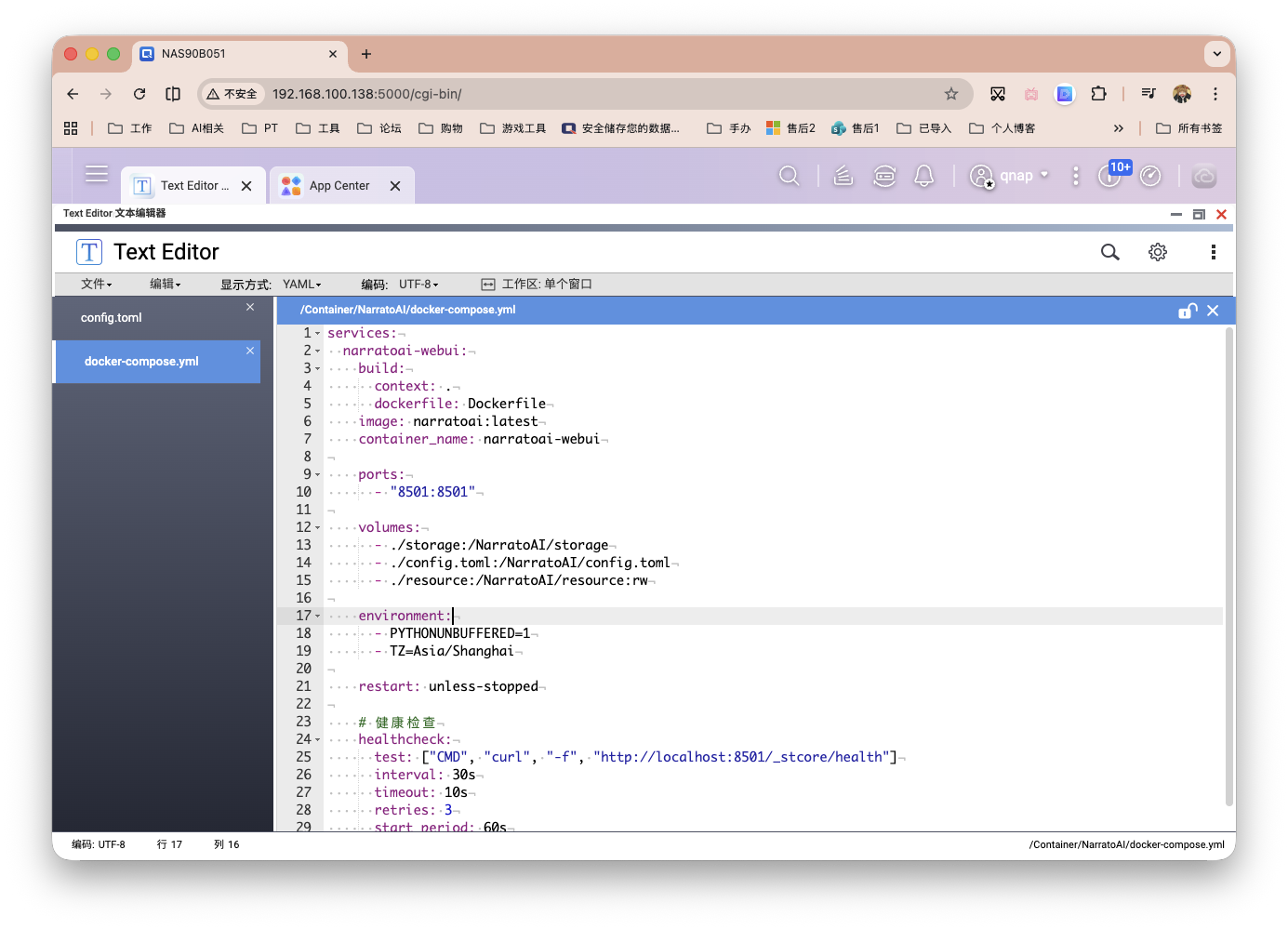
关于docker-compose.yml文件简单给大家看下,没什么大差,想要修改端口号,可直接执行vim docker-compose.yml或者在Web端利用NAS自带的文本编辑器修改。
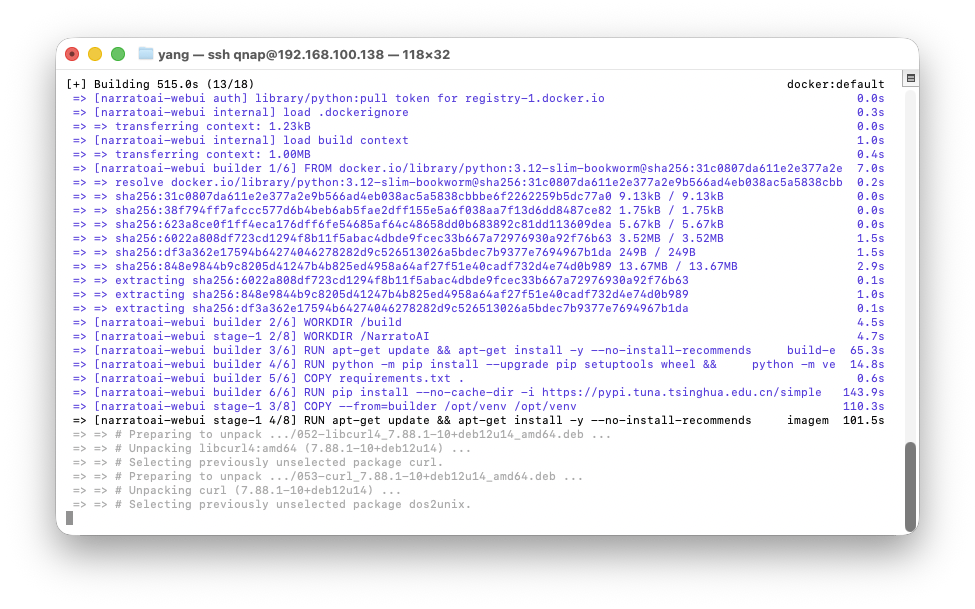
构建所花费的时间还是蛮久的,大概十分钟?大家耐心等待。
如果你创建启动失败,那大概率是文件权限问题,请给storage赋权。
使用展示
部署完毕后,浏览器输入NAS_IP:8501即可访问页面。如果你的页面是一堆红色报错,那概率可能是config.toml配置中的编码问题,文件必须保存成 UTF-8,可以将其中的所有中文注释删除,再跑一遍试试。
如下图左上角,可修改语言。其他配置写的也都很明确,大家自行查看。
普通的脚本、视频匹配,各自上传好后,脚本的文字会转为字幕,TTS转的语音都会在生成的视频中匹配上。
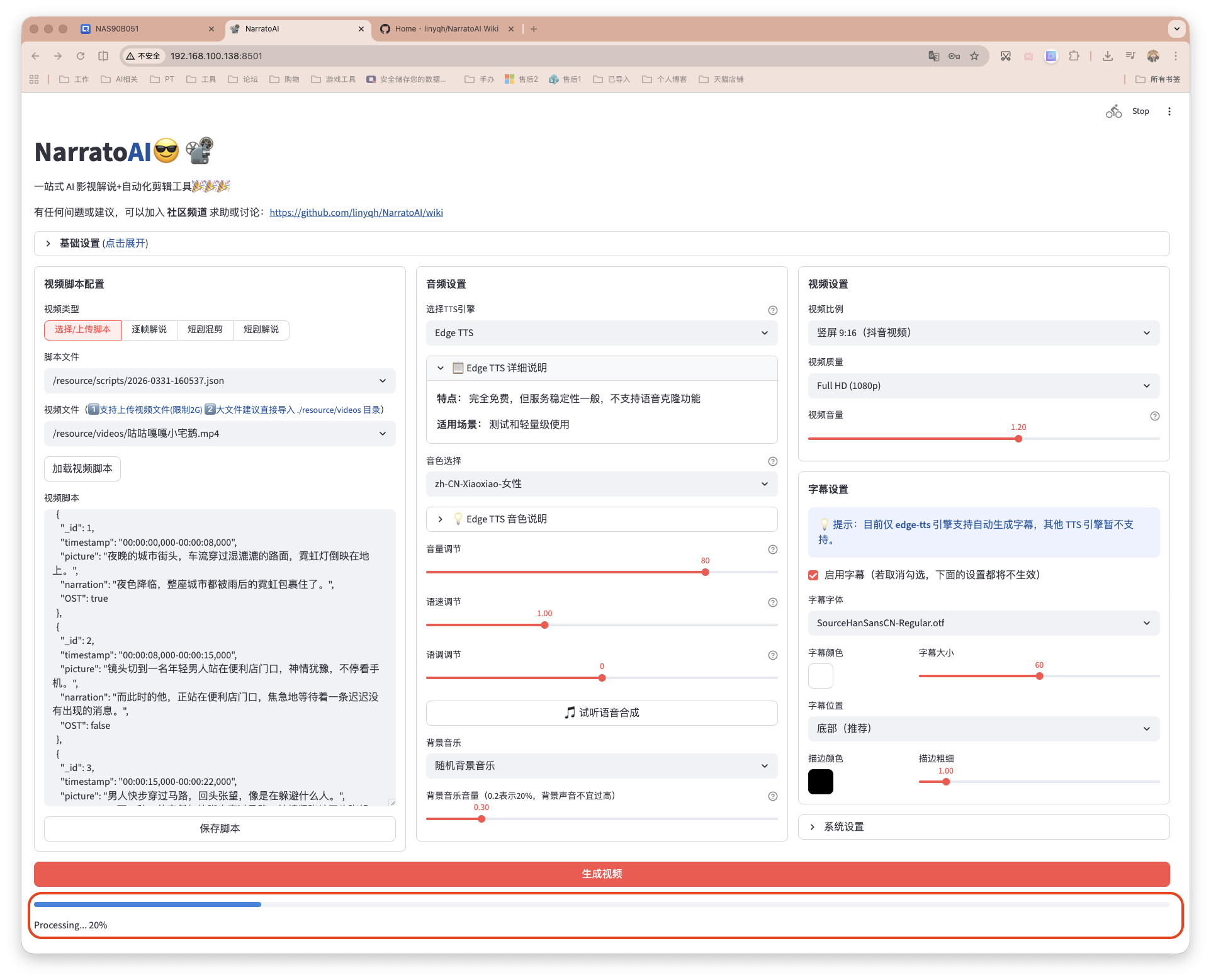
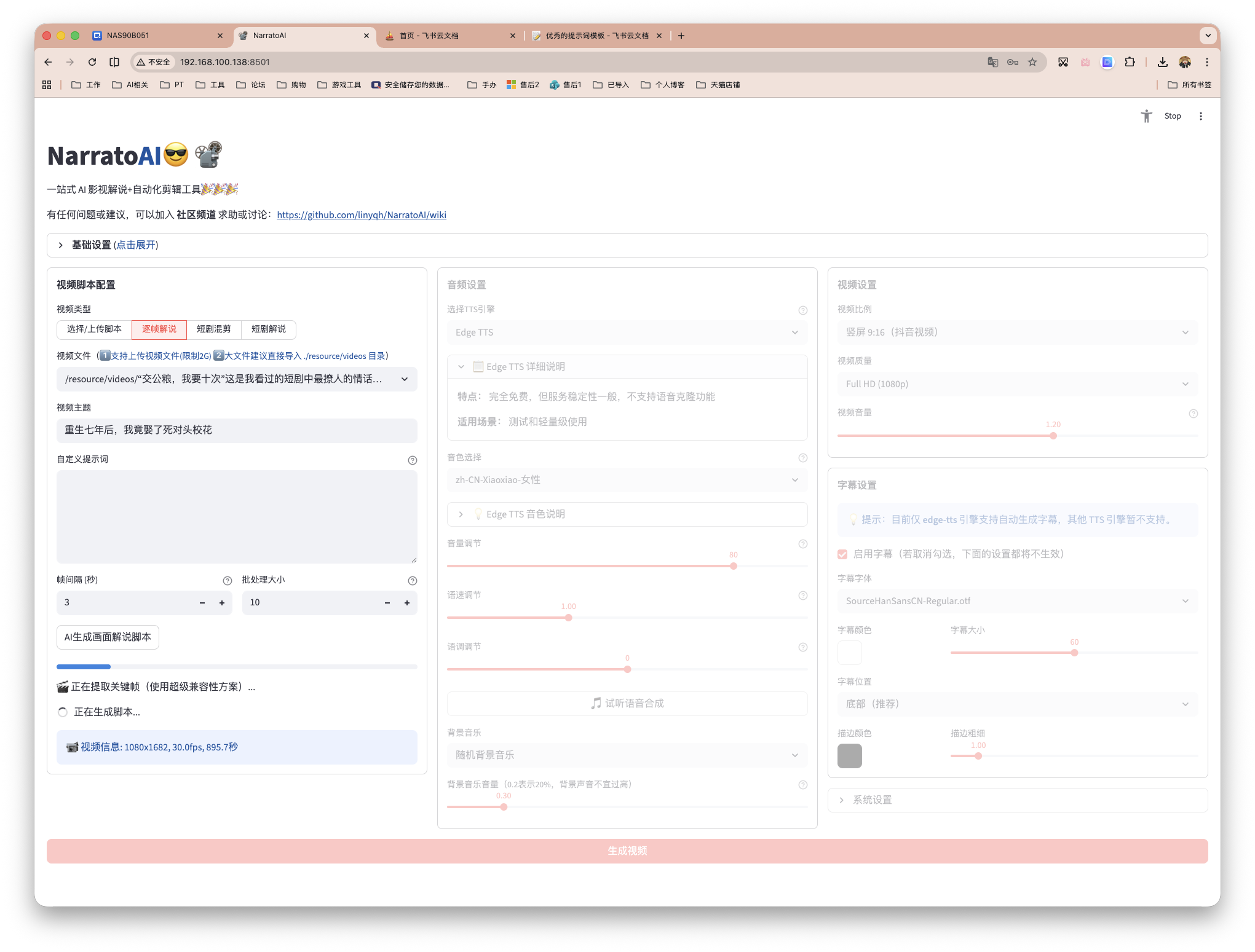
另外也可逐帧解说,通过抽帧,给出最终脚本。
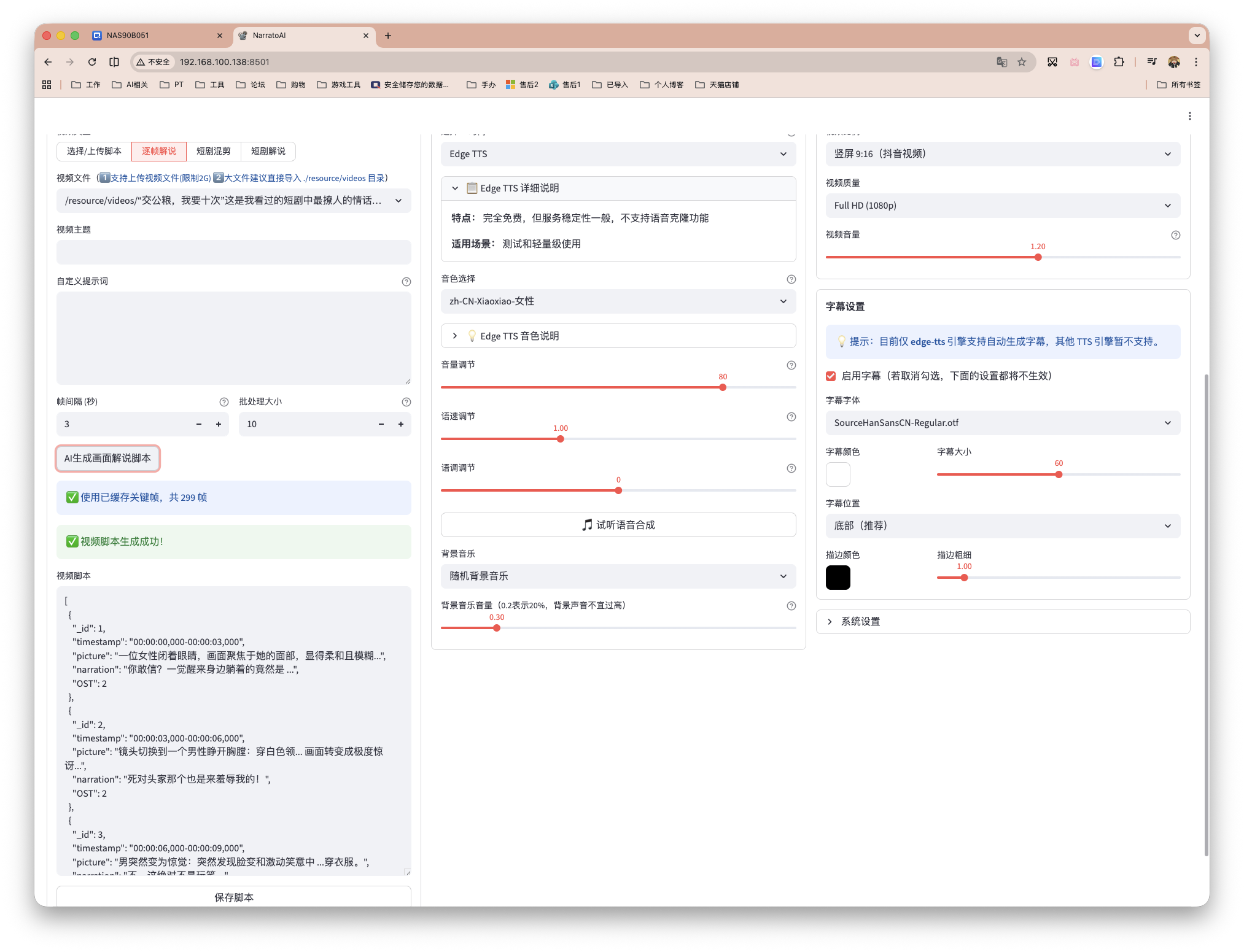
短剧混剪和短剧解说者需要字幕文件,这里我便不做继续的测试了~
最后
总之,这类项目还是挺值得搭来玩玩的。它能不能真正做出像样的东西,既看 AI 行不行,也看人会不会用。工具越来越聪明了,但脚本怎么写、内容怎么讲、节奏怎么控,这些事很多时候还是得靠人。
感兴趣的朋友可以部署个试试。
感谢观看,本文完。
评论区